How to optimise lambdas?
• 4 min read
Introduction
Lambdas are function as a service (FAAS). It enables us to move fast without worrying about servers on our own.
It is very productive for a small team as it is much easier to manage serverless lambdas instead of managing servers/containers directly. you trade off the ability to tweak the machine on your own for simplicity.
It is also ideal for a use case in which you don’t know about incoming traffic load and spikes. when your product is in a growth phase and there can be sudden spikes, lambdas are able to handle it because of built-in auto-scaling. If we use servers we will need to over-provision resources which can cost more. You will need to use complex tools like Kubernetes (and others) for auto-scaling servers, which requires at least one DevOps personal on the team.
How does Lambdas work?
Whenever a lambda needs to be invoked, a firecracker micro virtual machine is started by AWS on dedicated EC2 instances for each customer. your code is downloaded, the runtime is set up on this virtual machine and then the request is handled. After some time if no requests come (it’s around 15 mins) then this container is removed.
Firecracker is a lightweight micro virtual machine which uses KVM (Linux Kernel-based Virtual Machine).
Challenges
That doesn’t mean it is a silver bullet to all the problems. Lambdas come with their own challenges. we will first understand these challenges and then see how we can resolve these. Some of those problems are:
- Cold starts Cold starts happen when lambda is not invoked for some time or a new instance of lambda is created to handle more load. It can take 1-2 seconds which makes the first request handled by the lambda instance quite slow.
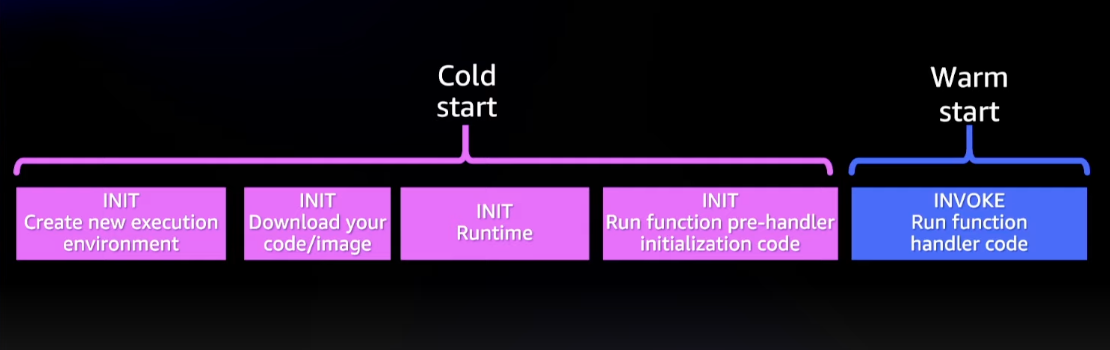
-
Managing connections to the database Since each lambda instance makes a new database connection, your database might get overwhelmed with huge number of connections if you have too many lambdas.
-
Debugging can be tough If you are following a microservice architecture and multiple lambdas are invoked to fulfill a user request, then it becomes hard to trace bugs.
Solutions
Provisioned Concurrency
we can set provisioned concurrency of lambdas which allows us to keep some instances of lambdas always warn and ready to go. This incurs some additional cost but lowers removes the cold start time.
so let’s say if we set provisioned concurrency for lambda as 5, then 5 instances of lambdas will always be warm and ready. so 5 concurrent requests can be handled without any cold start delay.
Another alternative to using provisioned concurrency to keep lambdas warm is to use a cron to trigger lambda you want to keep warm in some intervals.
Reuse database connections
Initialise database connections out of the handler function, so that you are not creating a database connection for each request. This will speed up the lambda by not waiting for a connection for each request and cleaning up after each request.
The only downside to this is that we can’t clean up the connection manually, to solve this we can use idle connection timeout. so that a connection can be reclaimed if it has been idle for some time (say 10 minutes)
Use database proxies
So consider your whole backend is running on lambdas. so you can easily have 100s of individual lambdas and considering there will be some concurrent requests, let’s say 10. That can mean 1000s of concurrent database connections which is poor resource utilization as each connection means additional RAM usage by the database (assuming Postgres).
So it’s better to use database proxies which will maintain a connection pool and our lambdas can use this connection pool maintained by proxy when required.
Use logging and monitoring tools
we use cloudwatch to monitor all the logs, resource utilization, and performance of the lambdas. we can also check how many cold starts are happening for a function using cloudwatch, specifically lambda insights in cloudwatch. this needs to be enabled manually and by default, it is turned off.
we use sentry.io for error tracking. we trigger a slack message whenever there is a new issue or some issue repeats a certain number of times in a time frame using sentry.
References:
https://aws.amazon.com/blogs/aws/firecracker-lightweight-virtualization-for-serverless-computing